Teorema CAP
Você já ouviu falar sobre o teorema CAP?
Não… não esse CAP. Vamos a Wikipedia:
"" Teorema do CAP, também chamado de Teorema de Brewer, afirma que é impossível que o armazenamento de dados distribuído forneça simultaneamente mais de duas das três garantias seguintes:
-
Consistência (Consistency): Cada leitura recebe a escrita mais recente ou um erro
-
Disponibilidade (Availability): Cada pedido recebe uma resposta (sem erro) - sem garantia de que contém a escrita mais recente
-
Tolerância a particionamentos (Partition tolerance): O sistema continua a funcionar apesar de um número arbitrário de mensagens serem descartadas (ou atrasadas) pela rede entre nós
Nenhum sistema distribuído está protegido contra falhas de rede, portanto, a partição geralmente deve ser tolerada. Na presença de partições, são dadas duas opções: consistência ou disponibilidade.
Ao escolher consistência em relação à disponibilidade, o sistema retornará um erro ou um tempo limite se informações específicas não puderem ser garantidamente actualizadas devido à sua partilha na rede.
Ao escolher disponibilidade sobre consistência, o sistema sempre processará a consulta e tentará retornar a versão disponível mais recente da informação, mesmo que não possa garantir que ela esteja atualizada devido às partições. ""
Versão super resumida: bancos de dados só podem escolher 2 dos 3 elementos. É matemáticamente impossível ter os 3.
E onde os bancos de dados atuais se encaixam?
Vamos à figura:
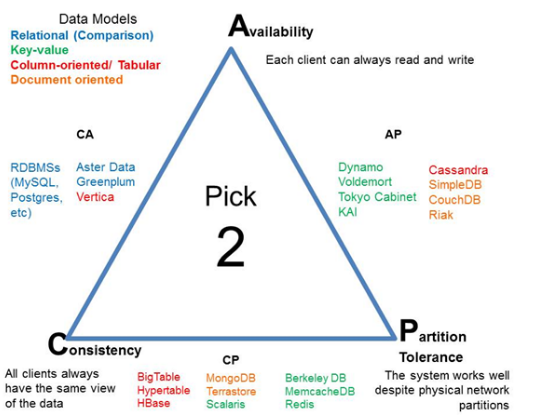
-
Consistency + Availability: como exemplos temos bancos de dados relacionais (Oracle, MySql, Postgre, MS SQL Server, etc). Tendo CA, eles não tem Partition Tolerance. Eles podem ter replicação, mas não partição. E aqui temos toda a parte de transação, locks de banco, etc
Mesmo sacrificando disponibilidade isso não deveria ser um problema se usado corretamente. Ex: fazer a aplicação conhecer todos os membros cluster, mudar o nodo em caso do atual falhar (e remover ele da lista de nodos válidos).
-
Partition Tolerance + Availability: aqui o mais conhecido é o Cassandra, usado pelo netflix. Não tenho experiencia com bancos PA, mas do que eu pude ver você pode selecionar a consistência durante a operação. Ex: views do youtube - não teria muito problema se retornasse 1004 ou 1007 views.
Considerações
-
RDBMS não fazem uso de computação distribuída, limitando a escalabilidade por hardware;-
Update: bancos como Google Cloud Spanner, CockroachDB, Amazon Aurora são exceções a essa regra (tks alanhoff do nodebr)
-
-
As vantagens dos bancos noSql vão alem da sintaxe, já que eles fazem uso de partição / cluster;
-
Bancos como mongodb não fazem uso de transação (commit / rollback). E nem possuem isso no roadmap. Para melhor uso desses bancos, pode ser usado um approach de Event Sourcing, onde não tenha alteração / exclusão de dados. Além de event sourcing ainda tem controles de consistência otimistas, tipo o que os Couch-like utilizam.
-
Divisão de hardware é algo a ser considerado para melhor performance. Ex: em bancos como hbase, é melhor ter múltiplos HDs menores do que um grande SSD, para paralelismo de IO;
-
O modelo de dados pode ser implementado em diferentes bases do CAP, como é o caso de bancos de dados tabulares: CA com Vertica, CP com HBase, PA com Cassandra.
Referencias
Updates
Obrigado especial ao @PEdrArthur pelo review e dicas.
Dúvidas? comentários? Sugestões? Ficou claro o conteúdo? Deixa um comentário aí abaixo.